数据为王:Enable AI 带你读懂 Data-Centric 模型研发新范式
2021年9月,Andrew Ng提出了Data-Centric AI的概念,开启了AI模型系统设计的新范式。

什么是 Data-Centric AI
Data-Centric AI is the discipline of systematically engineering the data used to build an AI system. — Andrew Ng
以往,我们训练一个AI模型的方式主要是在一个相对固定的数据集上不断迭代模型算法的网络结构和参数,这种训练方式以模型算法为中心(Model-Centric AI)。然而,Model-Centric AI在实际落地时通常因为过度专注算法设计的精巧而忽视数据带来的问题(广度、难度和保真度),如不准确标签、重复数据、异常数据等。
这使得准确率高的模型可以很好的拟合数据分布,但并不一定代表它会在实际应用中有好的效果,此外,低质量的数据可能会引发数据的级联反应,造成负面影响,例如准确性下降和持续偏差。这会严重阻碍AI系统的适用性,特别是在高风险领域。

随着Transformer为代表的算法架构出现,各场景下的模型架构逐渐走向大一统,例如:图像中的SAM、文本中的ChatGPT、语音中的Whisper、视频中的SEEM、自动驾驶中的FSD等。算法工程师们逐渐发现,数据在AI模型中的重要性越来越高。
2021年9月,Andrew Ng提出了Data-Centric AI的概念,开启了AI模型系统设计的新范式。
Data-Centric AI指在模型算法相对固定的前提下,重点关注和提升数据的质量、多样性和数量。
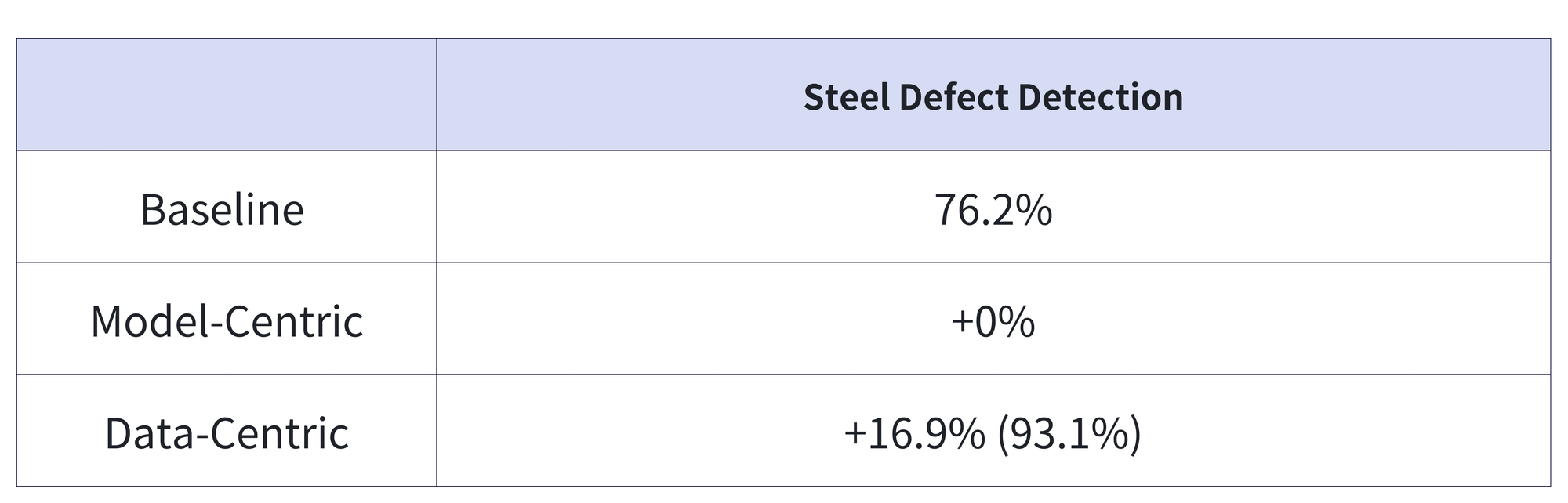
以常见的视觉检测算法(钢材检测)为例,在Baseline模型的基础上,更新模型网络结构和参数对模型效果的提升几乎没有收益,但提升数据的质量和数量却可以显著提升。
AI 领域的二八定律
If 80 percent of our work is data preparation, then ensuring data quality is the important work of a machine learning team.. — Andrew Ng
Andrew Ng通过对算法工作的观察,得出了AI领域知名的“二八定律”:一个好的AI系统=80%的数据+20%的模型。他认为算法工程师应该把80%的工作放在数据的准备上,尤其是海量高质量的数据准备上。
爱丁堡大学的博士生符尧发现,好的数据组合(data format, mix ratio, and curriculum)可以加快模型的学习速度。OpenAI的研究发现使用少量精选的数据可以有效改进模型的特定行为。
过往,大部分的算法工程师需要参与数据采集、标注、训练、参数调优等工作,随着数据量的上升,精细化数据组合的灵活性需求增强,算法工程师对数据的管理成本陡增,数据从采集到模型训练的流转效率也随之变慢。
深入 Data-Centric AI
系统框架
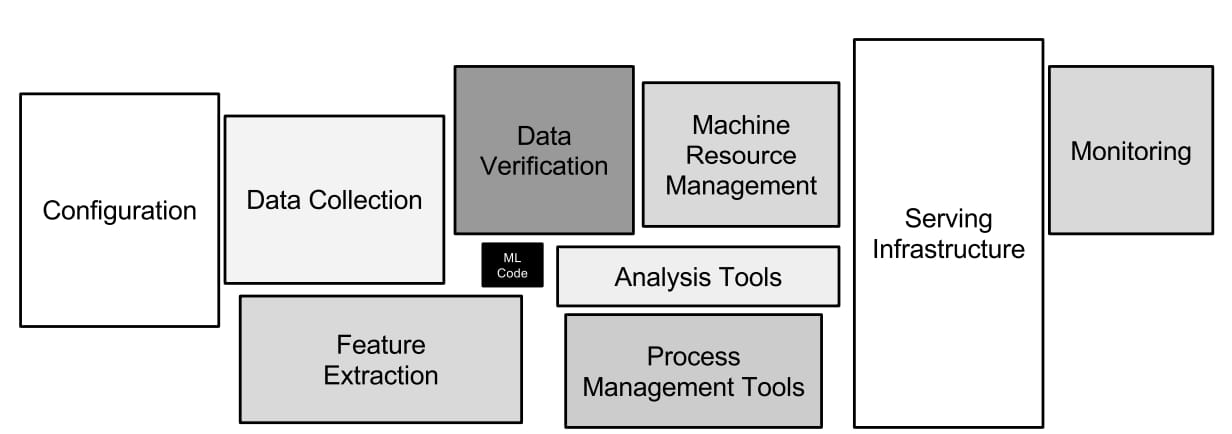
Data-Centric AI的建设目标是通过自动化和智能化的方式来生产高质量数据,加速AI全生命周期内的数据生产、迭代、组合、管理和洞察,进而提升AI产品的更新效率。
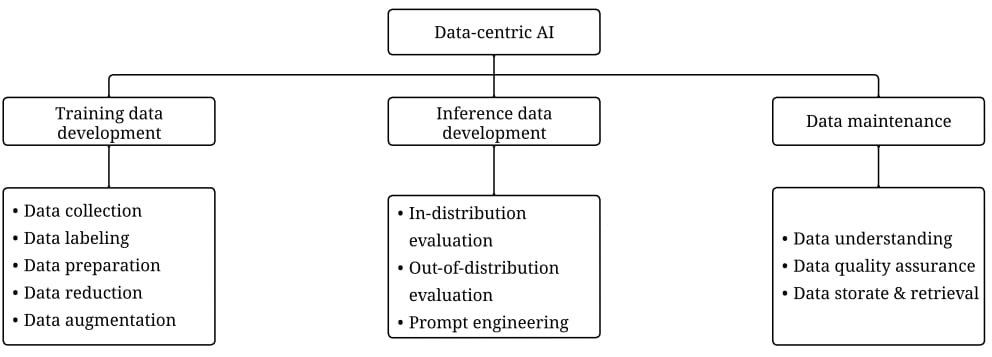
Data-Centric AI系统主要由三个部分组成:
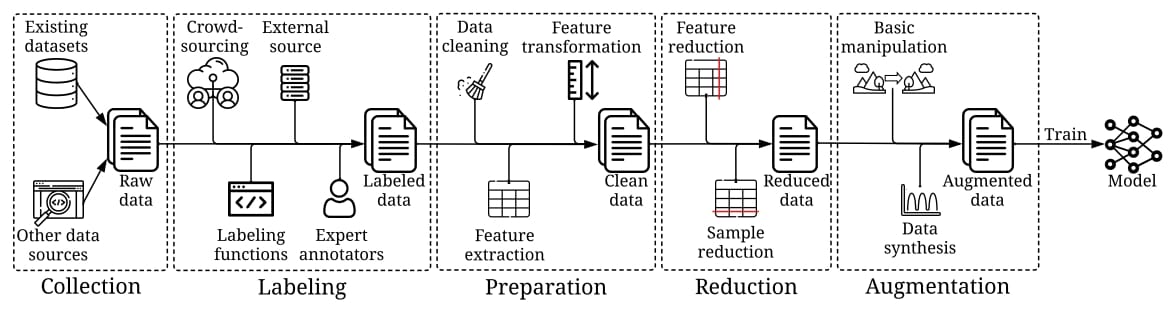
训练数据开发:目标是生产高质量的训练数据,来支撑机器学习模型的训练
- 数据收集:原始训练数据的采集,用于数据打标和无监督训练;如 数据爬虫、数据合成等
- 数据标注:多源语义标签的打标;如 BPO模式的人工标注、active learning中的human-in-the-loop等
- 数据准备:数据的清洗和转换,如 特征清洗、提取、转换等
- 数据压缩:数据容量的压缩;如特征抽取、降维等
- 数据增强:在不收集更多数据的情况下,丰富数据的多样性;如 数据增广策略和数据生成算法
推理数据开发:目标是创建新的模型推理数据集,用于细粒度评估和探索模型能力
- 分布内评估:与训练数据同分布的样本。例如:比较常见的数据切片、反事实样本(算法回溯)
- 分布外评估:不同于训练数据分布的样本,例如:自动驾驶中的难例场景数据合成仿真、攻防演练等
- 提示工程:优化prompt以获得最优解。例如:APE算法

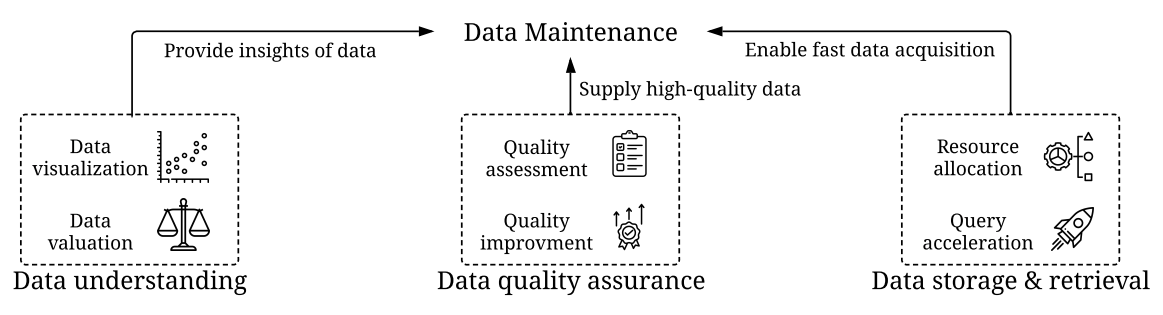
数据的管理和维护:是Data-Centric AI的基石,目标是确保动态环境中数据的质量和可靠性。在实际生产中,数据并非一次性创建,数据和模型都是在不断的更新和迭代,为此需要持续的维护和管理数据。
- 数据理解:提供复杂数据的可视化能力和评估能力,获得有价值的数据理解
- 数据的质量保证:用于监控和修复数据质量,提供数据质量的量化指标和改进策略
- 数据存储和检索:通过高效的算法来进行数据的调度、存储和检索
任务划分
围绕着AI数据生命周期的不同阶段,可以将Data-Centric AI划分成如下两类任务:
- 自动化:随着可用数据规模的不断增长,采用自动化的算法来简化流程。如自动化数据增强和特征转换。这类自动化任务不仅可以提高效率,还可以提高准确性。自动化可以促进结果的一致性,减少人为错误的引入
- 人机协同:人工参与对于确保数据符合我们的意图至关重要。例如,在标注数据的阶段,人工发挥了不可或缺的作用。是否需要人工参与取决于我们的目标是否是使数据与人类的期望保持对齐。
将目前Data-Centric AI的研究方向划分为两个视角,即自动化和人机协同。每个数据任务都有不同程度的自动化,并需要不同程度的人工参与,如下图:
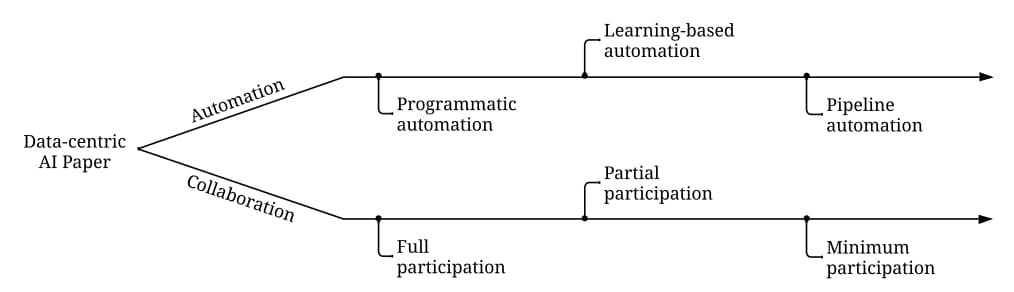
这两类研究方向中,前者侧重于自动化流程的设计,后者则更加关注human-in-the-loop的实现根据自动化程度不同,可以将自动化任务细分成三类:
- Programmatic automation: 使用程序自动处理数据。程序通常是根据一些启发式和统计信息进行设计。现阶段各类的automate machine learning的工作大都集中于此,例如各类auto feature engineering的方法
- Learning-based automation: 优化学习自动化策略。例如,最小化目标函数,此类方法通常更灵活适应性更强。例如基于强化学习的方法做超参数调优或基于 meta learning 来确定优化策略等。
- Pipeline automation: 跨多任务的自动化调整优化策略,帮助确定全局最优策略,但这类方法的调优也会引入更多的成本开销。例如tpot,autosklearn这类工作,将数据处理,特征工程,模型调参等一系列任务耦合在一个pipeline里(Learning-based automation和Programmatic automation可以看作是pipeline automation中的一环)
根据人工参与程度的不同,可以将人机协同细分成三类:
- Full participation: 完全参与。需要全员参与的方法通常可以很好地符合人类的意图,但代价高昂,例如BPO模式下,通过雇佣外包公司来做数据打标。
- Partial participation: 不需要人类全程参与,但是需要人工密集或持续地提供信息。例如,通过提供大量人工反馈或频繁的人工交互。比如Chatgpt中的RLHF。active learning 领域很多研究都是这个范畴。
- Minimum participation: 自动化的控制整个过程,只在少量场景中需要人类交互。人类只有在收到提示或要求时才会参与。当遇到海量数据和人力预算有限时,这种方法非常合适
从另一个角度看,人类的参与程度反映了效率(更少的人力)和有效性(更好地与人类保持一致)之间的权衡
典型案例
Instead of focusing on the code, companies should focus on developing systematic engineering practices for improving data in ways that are reliable, efficient, and systematic. — Andrew Ng
当前,Data-Centric AI已应用在多个领域的模型训练中,简要列举一二:
大模型
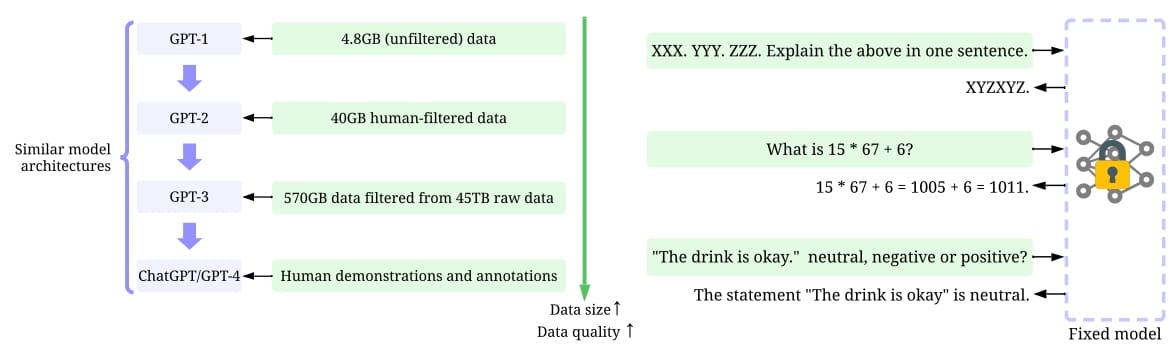
OpenAI的GPT模型(GPT-1、GPT-2、GPT-3、InstructGPT、ChatGPT、GPT-4)在训练时,模型设计并没有很显著的变化(除参数量外),数据的规模却越来越大,数据的质量越来越高,为保证数据标注的高质量,OpenAI花费了巨大的精力,甚至使用高学历的专用领域人才在精力最集中的时间段内进行数据的打标。
以RLHF(Reinforcement Learning from Human Feedback)为代表的强化反馈便是Data-Centric AI的一种,将数据、模型和人有机的结合起来,依靠learning from feedback(learning from human、ai、environment)思想实现模型的微调和数据的更新。
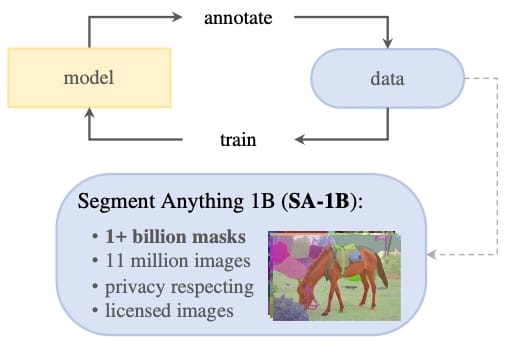
MetaAI发布的SAM(Segment Anything)模型被称为视觉AI能力的大一统。训练SAM的核心在于大量的标注数据。其中较为突出的贡献是高质量数据集的标注,该数据集包含10亿个mask,比已有的segmentation数据集大400倍。MetaAI的data engine 采用active learning 的方式进行数据的打标,实现半自动到自动化的数据标注流程。
自动驾驶
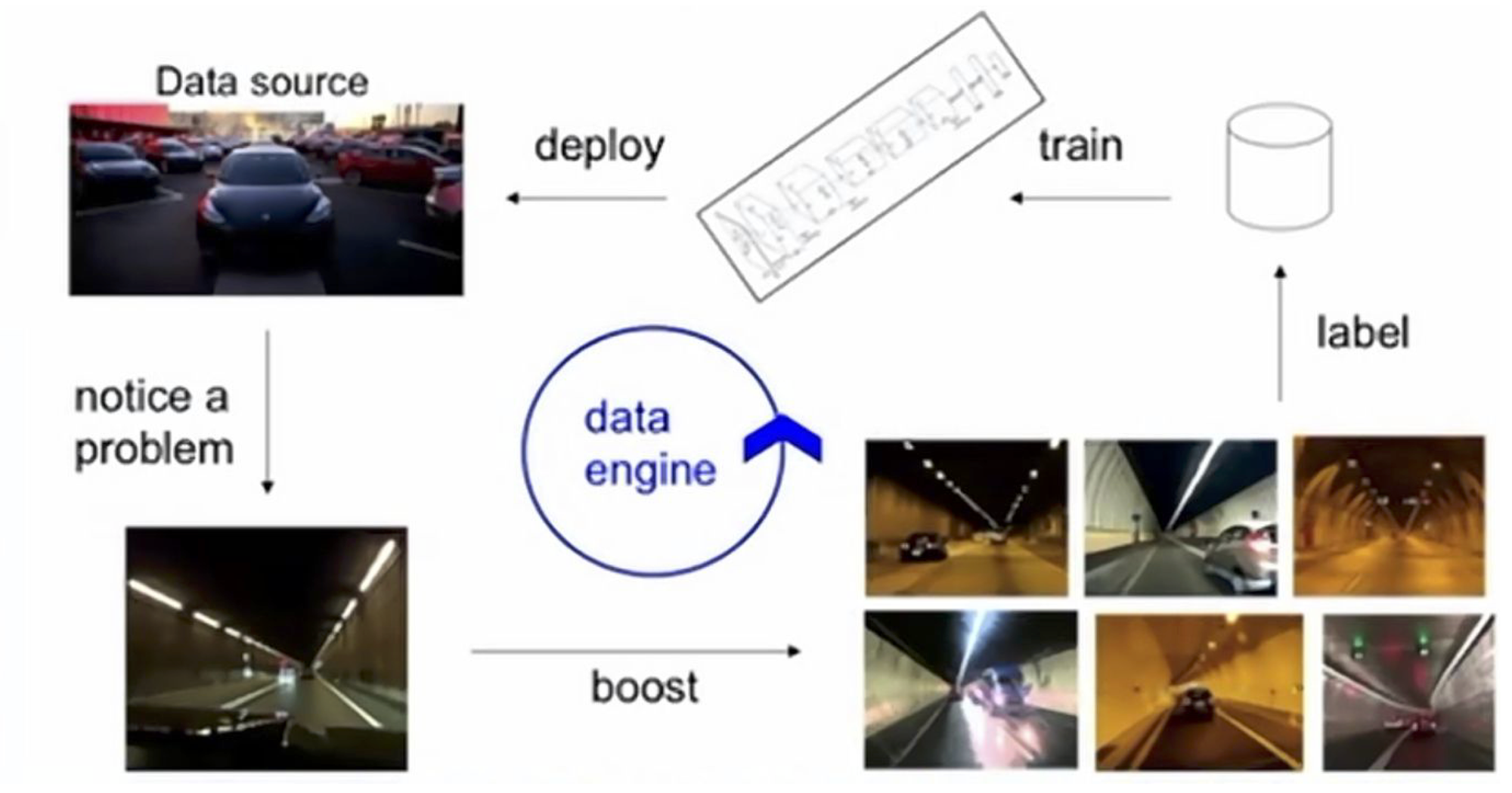
FSD自动驾驶系统是特斯拉在乘用车市场的杀手锏。特斯拉AI总监Andrej Karpathy坦言,特斯拉的FSD比同类竞争对手先进的核心因素在于数据引擎,即通过active learning 的方式,迭代模型来提升数据集质量
标注作为AI系统的重要一环,将会在Data-Centric AI的范式下发生巨大改变
从ChatGPT、FSD、SAM等技术的成功经验,我们发现:
- Data-Centric AI有望成为企业设计AI系统的通用解法
- 海量高质量数据的生产和精细化挖掘变得越发重要
- 数据和模型的边界会越来越模糊,数据和模型彼此之间的反馈作用会越来越强
- 标注作为AI系统的重要一环,将会在Data-Centric AI的范式下发生巨大改变
关于 Enable AI
EnableAI是一家围绕AI模型全生命周期的数据服务提供商,既是Data-Centric AI的实践者也是赋能者
EnableAI从诞生之日起,便以Data-Centic AI思想为核心,重构数据标注流程,推动主动学习,小样本学习等技术在数据标注行业的落地,构建辅助AI,质检AI,预标注AI以及任务调度AI。实现数据质量和标注效率的提升。于此同时EnableAI也在不断的丰富其在海量非结构化数据管理、成品数据集、多源异构弹性数据/模型计算、多场景MAAS平台、AI模型/数据治理体系等方面的建设
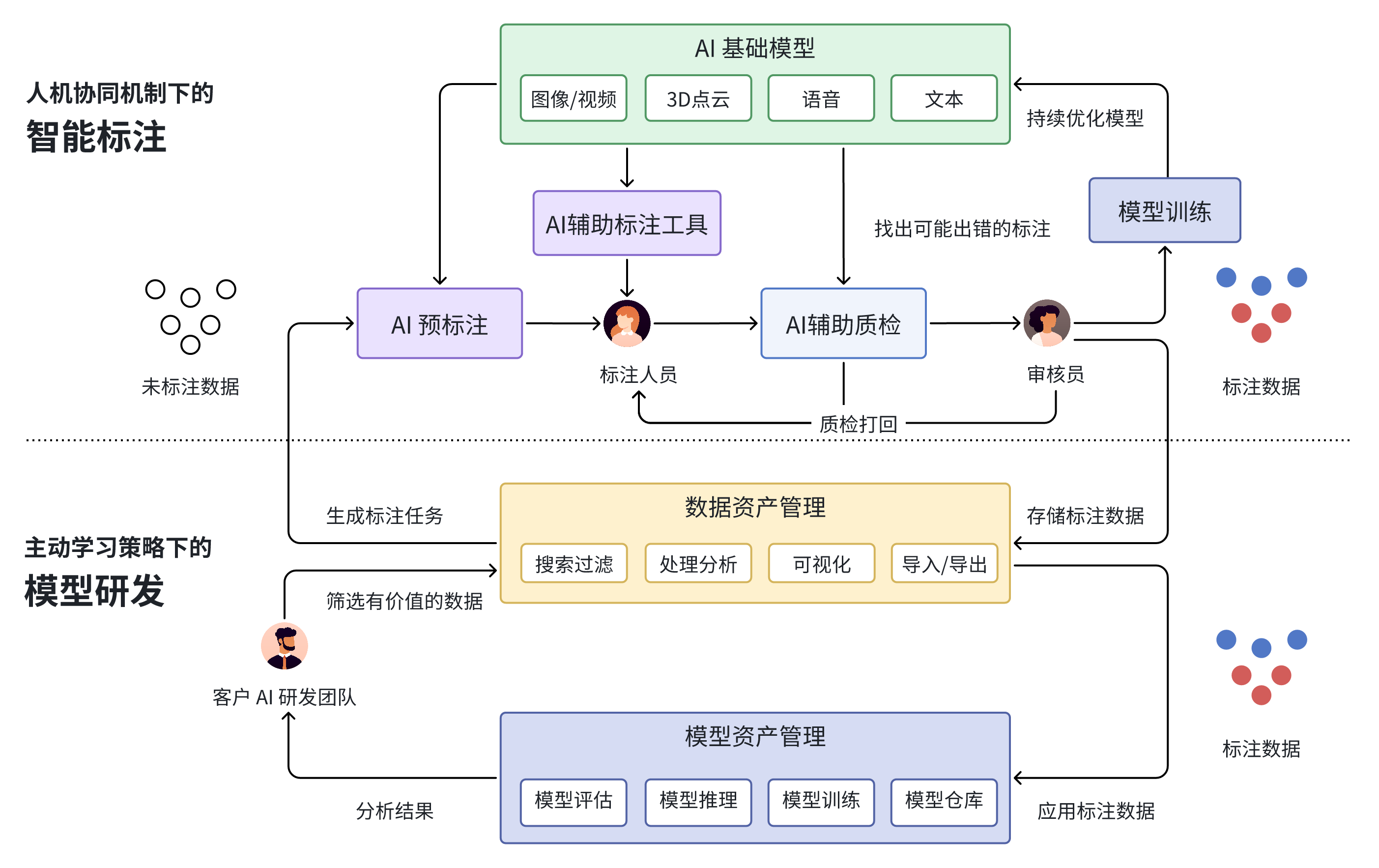
在模型积累上,EnableAI完成上百个模型的调优和适配工作,方向包括图像分类、关键点检测、车道线检测、目标检测、文字识别、图像分割、多目标跟踪、语义分割、文本生成、视频理解等,场景覆盖文本、语音、图像、视频、自动驾驶、大模型
在自动驾驶领域(特指智能座舱和辅助自动驾驶),EnableAI完成了4D BEV点云融合、3D连续帧多目标跟踪、3D点云检测/分割等算法集成。尤其在4D BEV点云融合场景重建中,相对于传统人工标注,EnableAI的标注效率提升了10倍
在大模型领域,EnableAI服务于多家头部大模型厂家的标注和审核业务,累计培养金融、数学、外语、编程、文学等专有领域近百人,在成品数据集构建、数据安全清洗、攻防演练等方面也在现实场景中得到验证并持续推进中
截止目前,EnableAI在全国有5个数据生产基地、累计培养数据标注审核人员5w+,客户广泛分布在互联网、自动驾驶、大模型等领域

One More Thing
EnableAI始终致力于为客户提供优质数据服务,帮助客户高效落地AI应用。为实现该目标,我们认为高密度的人才组织和自下而上的创新是EnableAI持续进步的基石,期待每一位有识之士的加入,也期待每一位关爱EnableAI的人能够为EnableAI的建设提供宝贵的建议
招聘岗位:
- 高级前端工程师:海量点云数据的性能优化
- 高级后端工程师:高并发场景下的架构设计、安全防护
- 高级数据工程师:多源异构的数据存储和弹性计算
- 高级算法工程师:主动学习、小样本、弱监督算法的优化
岗位联系:hr@enableai.cn
参考资料
- Data-centric Artificial Intelligence: A Survey
- Hidden Technical Debt in Machine Learning Systems
- Data-centric AI: Perspectives and Challenges
- “Everyone wants to do the model work, not the data work”: Data Cascades in High-Stakes AI
- Challenges in Deploying Machine Learning: a Survey of Case Studies
- OpenGSL: A Comprehensive Benchmark for Graph Structure Learning
- Big Data To Good Data: Andrew Ng Urges ML Community To Be More Data-Centric And Less Model-Centric
- Building the Software 2.0 Stack Andrej Karpathy (Tesla)
- Notion – The all-in-one workspace for your notes, tasks, wikis, and databases.
- DC-CHECK: A DATA-CENTRIC AI CHECKLIST TO GUIDE THE DEVELOPMENT OF RELIABLE MACHINE LEARNING SYSTEMS
- Segment Anything
- Training language models to follow instructions with human feedback
- Illustrating Reinforcement Learning from Human Feedback (RLHF)
- RLAIF: Scaling Reinforcement Learning from Human Feedback with AI Feedback
- Deep Reinforcement Learning from Human Preferences
- Summarizing books with human feedback
- Improving language model behavior by training on a curated dataset
- What Are the Data-Centric AI Concepts behind GPT Models?
- Understanding the Capabilities, Limitations, and Societal Impact of Large Language Models
- GPTs are GPTs: An Early Look at the Labor Market Impact Potential of Large Language Models



