边标边训:Enable AI如何利用主动学习策略节省90%标注成本
机器学习作为一种能够从数据中学习规律并进行预测和决策的技术,已经成为推动技术进步和创新的重要工具。
前言
机器学习作为一种能够从数据中学习规律并进行预测和决策的技术,已经成为推动技术进步和创新的重要工具。然而,机器学习模型的性能高度依赖于所用数据的质量和数量。因此,数据的重要性在机器学习中不言而喻。
数据标注的高成本和挑战
尽管数据在机器学习中扮演着关键角色,但获取高质量的标注数据往往是一个昂贵且耗时的过程。数据标注涉及到人工对数据进行分类、标记或注释,以便机器学习模型能够从中学习。然而,这一过程通常需要大量的人力投入,特别是在需要专业知识的领域。数据标注的成本主要体现在以下几个方面:
- 人力成本:聘请专业人员进行数据标注需要支付相应的报酬,尤其是在需要高度专业知识的领域。
- 时间成本:数据标注过程通常需要耗费大量时间,这不仅影响项目进度,还可能拖延产品的上市时间。
- 一致性和准确性:确保所有标注人员按照统一的标准进行标注,以保证数据的一致性和准确性,这本身也是一项挑战。
此外,随着数据规模的不断扩大,手工标注的成本和难度也随之增加。因此,如何有效地减少数据标注成本,成为了许多企业和研究机构面临的重要课题。
Enable AI 带来的解决方案
EnableAI 是热热数据旗下产品,以数据为中心,打造人机结合的智能数据标注平台,通过智能标注算法实现辅助标注和自动标注,同时提供数据管理和模型训练等AI全栈解决方案,帮助客户快速高质量的实现 AI 模型研发和应用落地。为了解决数据标注的难题,Enable AI 提供了智能、可扩展的数据标注工具,在人机协同的标注模式下,实践边标边训的主动学习策略,可大幅提高标注效率,节省标注成本。
什么是主动学习策略
Burr Settles[1] 的文章《Active Learning Literature Survey》详细地介绍了主动学习:“主动学习是机器学习的一个子领域,在统计学领域也叫查询学习或最优实验设计”。主动学习方法尝试解决样本的标注瓶颈,采用“边标边训”的策略,通过主动优先选择最有价值的未标注样本进行标注,以尽可能少的标注样本达到模型的预期性能。
主动学习的基本流程
如下图所示,主动学习方法是一个迭代式的交互训练过程,主要由五个核心部分组成,包括:
- 未标注样本池(unlabeled pool,记为U)
- 筛选策略(select queries,记为Q)
- 标注者(human annotator,记为S)
- 标注数据集(labeled training set,记为L)
- 目标模型(machine learning model,记为G)
主动学习将上述五个部分组合到同一个流程中,并通过如下图所示的顺序,以不断迭代的训练方式更新模型性能、未标注样本池和标注数据集,直到目标模型达到预设的性能或者不再提供标注数据为止。
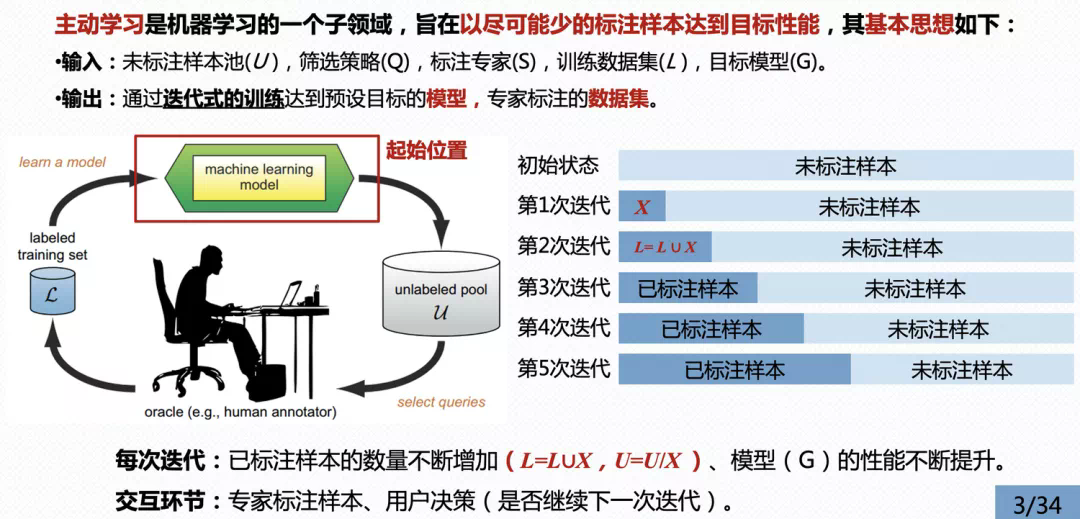
其中,在每次迭代过程中,已标注样本的数量不断增加,模型的性能也随之提升(理想情况)。在实际应用中,应尽可能保证标注者的准确率,缓解模型在训练初期学偏(此处特指错误标注的样本导致)的情况。
训练数据的选择
主动学习的核心在于选择性标注数据,即通过特定的查询策略,优先选择那些对模型训练最有帮助的数据样本进行标注。不同于传统的随机标注方法,主动学习能够最大化利用每一个标注数据,提升整体标注效率。在主动学习过程中,数据选择策略的选择至关重要。以下是几种常见的主动学习策略:
- 不确定性采样:选择模型预测最不确定的样本进行标注。这些样本通常位于决策边界附近,对模型的改进最为显著。例如,在图像分类任务中,选择那些模型预测置信度最低的图像进行标注。
- 多样性采样:选择数据集中具有最大多样性的样本进行标注,确保模型能够学习到更全面的信息。这种策略尤其适用于数据分布不均的情况,通过增加数据的多样性,提升模型的泛化能力。
- 错误率最大化:选择模型预测错误率最高的样本进行标注。这种策略能够快速修正模型的错误,提高模型的准确性和鲁棒性。
- 混合策略:结合不确定性采样和多样性采样等多种策略,综合考虑样本的不确定性和多样性,选择最优样本进行标注。这种方法能够更全面地提升模型性能。
例如,在训练自动驾驶场景下的目标检测(人/车/电动车)任务时,我们可以选择根据模型预测的置信度来选择下一步要进行标注和训练的数据,置信度低则表示该样本模型预测不准确,属于难样本,可以用来训练。或者比如我们发现模型在行人这个类别上效果较差,那我们也可以选择行人更多的数据来进行标注和训练。以上只是最简单的两个例子,实际上我们可以应用更复杂的混合策略来选择数据,使得我们在“边标边训”的主动学习标注流程中能够使用更少的人力标注得到更准确的模型,以达到更有效节约成本的目的。
Meta 的应用案例
接下来我们分析一个经典案例——Meta 的 SAM 模型,利用主动学习策略,Meta开发了史上最大的分割数据集 SA-1B,包含超过10亿个掩码图和1100万张图像,实现了通过零样本学习在多种图像分布和任务中的快速适应。

整个标注过程也实现了“边标边训”的理念,交互式的标注图像并更新模型,多次重复循环以改善模型和数据集,实现人机协同(Human in the loop)和模型辅助标注(Model in the loop)的新范式。
整个过程分为三个阶段:
第一阶段:模型辅助标注
- 用公开数据集训练一个初始版本的SAM模型,使用这个初版模型辅助标注前景和背景点生成mask,用笔刷和橡皮工具做精细化调整
- 标注员可以任意标注语义,仅标注他们认识的物体,没有固定的标签规范
- 先标注突出显眼的物体,一旦一个mask要标30s以上,则跳过到下一张图片
- 使用新标注的数据重新训练SAM模型,算法架构也在调整,总计训练6次
- 每个mask平均标注时间从34秒下降到14秒,每张图片的mask数也从20涨到了44
- 此阶段使用了120k张图片,总计标注4.3M个mask
第二阶段:半自动标注
- 自动检测置信度高的mask,展示给标注员,并让标注员标注其他物体,从而增加mask的丰富性
- 用第一阶段的mask数据训练一个目标检测模型,检测置信度高的mask
- 此阶段使用了180k张图片,总计收集5.9M个masks
- 除去自动标注的mask,剩下的mask比较有挑战性,因此标注时间增加到34秒一个mask,平均每张图片的mask数量从44个增加到了72个
第三阶段:全自动化标注
- 上个阶段后,数据量和mask丰富程度已经足够多了,训练出的模型可以识别模糊案例,形成了最终版模型
- 此时剩余数据全部由模型自动标注,结果使用 IoU 预测模块来选择置信度高的mask,且过滤重复mask
- 最终,由人工标注和模型自动标注协同,整个项目共标注了 1100 万张图,包含 11 亿个高质量 mask
Enable AI 如何实践主动学习策略
与 SAM 的 SA-1B 开发数据集的过程类似,为了在数据生产过程中实践“边标边训”的主动学习策略,Enable AI 将模型训练能力引入标注平台,同时提供了标注结果的可视化展示功能。标注团队只要人工标注少量数据就可以训练出一个辅助标注模型,然后用这个模型自动标注剩余数据,筛选出置信度高的模型推理的结果作为预标注结果导入到人工任务队列中,经过人工审核后转换为真值数据。此时,项目经理可以再次启动模型训练程序,训练一个性能更好的辅助标注模型。一般情况下,经过4~5次迭代,即可得到一个可以令人满意的辅助标注模型由于审核预标注数据所消耗的人力成本远低于人工标注,因此用辅助模型预标注可以达到大幅节省人力成本的效果。同时借助高质量标注模型,生产出的数据质量也更高。Enable AI 平台训练出的模型仅可用于自动标注环节,不会被用于其他用途,也不会泄露任何客户数据。如果客户有特殊要求,平台也支持私有化部署。目前 EnableAI 标注平台已经在视觉标注任务中支持了主动学习流程,以相关领域的SOTA模型为基座微调辅助标注模型,具体包括:
- 图像分类任务
- 目标检测任务
- 图像语义分割任务
- 视频连续帧追踪任务
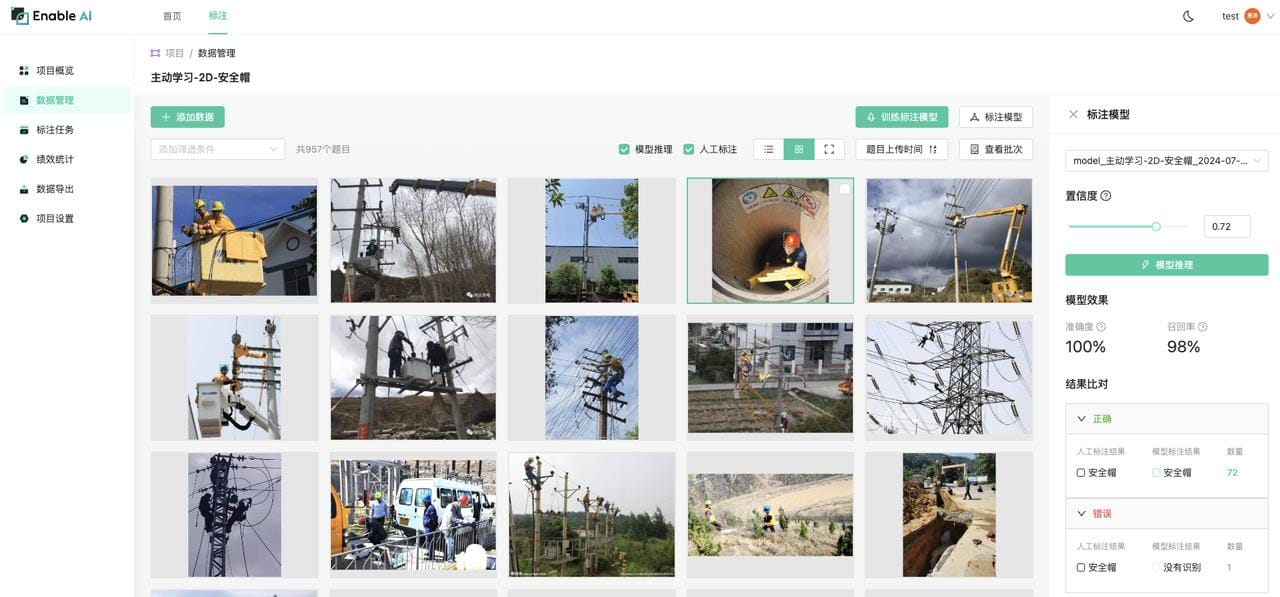
在简单场景的2D检测任务中,例如安全帽检测任务,根据实测,仅需不到50张图像便能训练出一个准确度接近100%、召回率达98%的模型。这意味着后续只有约2%的数据需要人工标注,相当于直接节省了90%以上的人力标注成本。在复杂场景下,可能需要更多人工标注工作,但至少也可以节省10%~30%的成本。
结语
随着大模型的横空出世,各类模型结构逐渐趋同,AI 研发也逐渐从“以模型为中心”过渡到“以数据为中心”。对数据规模和质量的关注催生了行业内对主动学习策略的大规模实践,“边标边训”的模式造就很多成功的模型,比如著名的SAM 模型,为行业贡献了规模更大的数据集。Enable AI 作为一家主打智能标注的数据服务商,我们致力于在数据标注过程中实践主动学习策略,希望提高数据质量和标注效率,为客户节省成本。目前 Enable AI 平台上已经支持了大部分视觉数据的标注任务,未来平台上将会支持更多场景的标注任务,如自动驾驶3D点云标注、语音标注,文本标注等,实践人机协同理念,为客户提供更优质的数据服务。



